Abstract
Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.Model
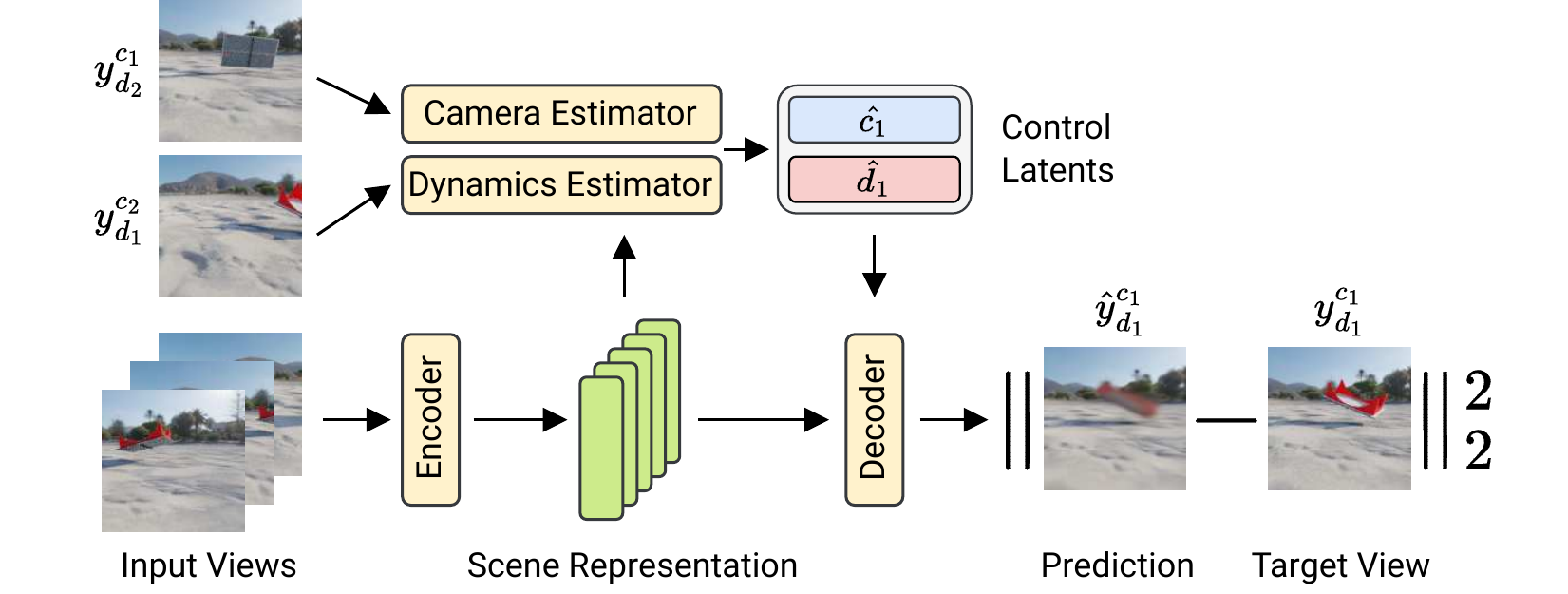
The Dynamic Scene Transformer (DyST) learns a decomposed representation of a dynamic scene into scene content, camera pose and dynamics that allows for controllable video generation. DyST is trained by synthesizing novel views using the camera and dynamics control latents. By estimating these control latents from views with matching camera and dynamics on synthetic data, a separation between camera and dynamics is induced. This separation is then transferred to real world video through a co-training scheme. At test time, DyST allows video generation with separate control over camera and content from a few input frames of a real video.
Examples and Visualizations
PCA Analysis and Latent Manipulations (DySO dataset)Video Manipulations
DySO Dataset
The DySO dataset is similar to SRT's MultiShapenet dataset. Each scene consists of 25 frames, arranged into 5 different object poses from 5 different camera positions. That is, the frames named "camera_0", "camera_5", "camera_10", ... have the same camera position, but the object has a different pose. The path to the DySO dataset is the following:builder = sunds.builder('kubric:kubric/msn_ms_v4.3a').
Please see SRT Website (Dataset) for detailed
instructions on how to load the dataset.
Related Projects
Scene Representation Transformer (SRT)Really Unposed SRT (RUST)
Reference
@inproceedings{seitzer2023dyst,
author = {
Seitzer, Maximilian
and van Steenkiste, Sjoerd
and Kipf, Thomas
and Greff, Klaus
and Sajjadi, Mehdi S. M.
},
title = {{DyST: Towards Dynamic Neural Scene Representations on Real-World Videos}},
booktitle = {The Twelfth International Conference on Learning Representations (ICLR)},
year = {2023},
url = {https://openreview.net/forum?id=MnMWa94t12}
}